
Descrição do Problema
O Censo é um procedimento sistemático para coleta de dados de uma determinada população. Esses dados tem caráter sócio-econômico e são usados para realizar estudos estatísticos. Alguns exemplos de estudos são: determinar porcentagem da população de cada sexo, determinar como é o modo de vida e de trabalho da população, etc.
A divisão regional dos estados dos Estados Unidos da América (EUA) nasceu dos primeiros Censos realizados. Eles utilizaram os dados coletados para dividir grupos da população com características parecidas. Adicionalmente, eles consideraram a distância geográfica entre os estados.
Com o passar dos anos, a população de um país pode mudar bastante em vários sentidos. Vários fatores contribuem para mudanças, como, por exemplo, nível de escolaridade (que tende a aumentar com o passar dos anos), aspectos migratórios, culturais, etc. Com essa ideia, nós questionamos o modelo de divisão regional dos EUA e, utilizando os dados do Censo, propomos verificar se essa divisão regional pode ser utilizada para agrupar sua população atual de acordo com suas característas socio-econômicas. Em outras palavras, será que a divisão regional realizada há décadas seria compatível com uma divisão realizada hoje, utilizando os dados do Censo atual?
Esse foi o objetivo principal do projeto e sua solução pode ser resumida em uma análise de agrupamentos. Naturalmente, para realizar uma análise como essa, foi muito importante adquirir um profundo entendimento sobre os dados fornecidos e seus significados. Portanto, para alcançar essa meta, também realizamos uma análise exploratória dos dados, e extraímos estatísticas e informações presentes no conjunto de dados.
Para acesso aos dados e sua descrição, bem como algumas informações úteis sobre o Censo, acesse o link
Metodologia
Para resolver esse problema, escolhemos inicialmente, trabalhar com a software Knime. O Knime apresenta uma série de ferramentas básicas que, através de uma interface bastante amigável, consegue resolver grande parte dos problemas de mineração de dados. Contudo, esbarramos em limitações técnicas e tivemos que desenvolver nosso trabalho em outro software, o MATLAB. O MATLAB é um software poderosíssimo que possui inúmeras bibliotecas que permitem realizar praticamente qualquer tarefa.
A metodologia utilizada para abordar esse problema pode ser dividida em duas partes:
- tratamento das variáveis;
- análise de agrupamento.
Através dessas duas etapas, vamos preparar os dados para serem analisados, extrair informações úteis e aplicar técnicas de mineração para obter resultados e avaliar nossa proposta.
Tratamento das Variáveis
Antes de qualquer coisa, é essencial realizar um tratamento nos dados brutos para que se possa realizar uma extração de informação mais eficiente. O dataset original é muito grande, possui aproximadamente 2GB descompactado (~200 variáveis e ~3,000,000 de registros). Por isso, a aplicação de qualquer algoritmo requer tamanho igual ou maior de memória disponível, bem como bastante poder computacional para terminar os cálculos em tempo viável. Precisamos, portanto, tratar os dados para reduzir o tamanho do dataset e, ao mesmo tempo, preservar o máximo de informações.
Com o intuito de nos ajudar nessa tarefa, classificamos as variáveis em três tipos: variáveis de controle, variáveis base e variáveis detalhadas. As variáveis de controle são informações técnicas utilizadas pelo próprio Censo para melhor administrar os dados coletados e, por isso, contém pouca informação útil sobre os indivíduos. As variáveis base são aquelas que introduzem uma categoria de variáveis e, portanto, apresentam informações básicas sobre os indivíduos. As variáveis detalhadas são especializações das variáveis base e trazem informações mais detalhadas sobre determinado aspecto individual.
Seleção das Variáveis Mais Significativas
Para cada tipo de variável mencionada, fizemos o seguinte tratamento:
- Variáveis de Controle: Todas essas variáveis foram removidas, uma vez que só fazem sentido para aqueles diretamente envolvidos no projeto do Censo. Além de diminuir o tamanho de variáveis e do dataset consideravelmente, acreditamos que a remoção de tais variáveis nos ofereça uma análise dos dados menos tendenciosa.
- Variáveis Base: Todas essas variáveis foram mantidas. Tais variáveis dizem bastante sobre o indivíduo ao mesmo tempo que tratam aspectos mais gerais tornando o problema mais simples. Baseamos nossa solução ao problema principalmente nessas variáveis.
- Variáveis Detalhadas: Essas variáveis puderam ser mescladas e, posteriormente, integradas ao conjunto de variáveis base. Por exemplo, temos no dataset original diversas variáveis que especificam algum tipo de deficiência. Essas variáveis foram excluídas e a partir delas foi criada uma nova variável final binária chamada deficiente, que simplesmente diz se um indivíduo possui ou não deficiências. Com isso, perdemos um pouco do detalhe, mas não prejudicamos a análise, uma vez que a correlação com as variáveis iniciais é proporcional.
“Categorização” das Variáveis
Como pretendemos realizar análises de agrupamentos, precisamos calcular a distância entre registros. Como temos dados com variáveis de diversos tipos, escolhemos transformar todas as variáveis em categóricas, definindo cada categoria para diferentes faixas de valores. Uma vez que todas as variáveis são categóricas, fica mais fácil para criar métodos de calcular distâncias. Como exemplo de “categorização” das variáveis, podemos citar a variável idade. Inicialmente, essa variável era numérica e refletia a idade do indivíduo. Depois de sua categorização, essa variável começou a representar faixas de idade, tais como criança, jovem, adulto e idoso e cada registro foi alocado em uma categoria baseando-se na idade anteriormente definida.
Redução das Categorias
Antes de passar ao próximo passo, é importantíssimo reduzir o número de categorias de cada variável. Se fizermos as escolhas adequadas, podemos reduzir o dataset sem perder muita informação sobre os indivíduos. Por exemplo, tínhamos a variável local_origem que especificava exatamente qual estado dos Estados Unidos ou qual país a pessoa é original. Existiam centenas de categorias possíveis. Visando diminuir esse número de possibilidades, criamos a variável região_origem que é uma especialização da variável local_origem. A variável regiao_origem possui apenas 8 categorias: EUA (obviamente maior grupo), América do Norte (excluindo-se EUA), América Central, América do Sul, Europa, África, Ásia e Oceania.
“Binarização” das Variáveis
Como usamos a Similaridade de Jaccard para calcular a distância entre os registros, precisamos transformar todas as variáveis em binárias. Existem duas técnicas para binarizar variáveis categóricas:
A primeira considera que cada categoria é uma nova variável binária. Por exemplo, considere a variável meio de transporte que tem as categorias carro, moto, taxi e ônibus. Ao binarizar essa variável, teremos um dataset com quatro variáveis chamadas carro, moto, taxi e ônibus que terão valor 0 ou 1 e são mutualmente exclusivas.
A segunda codifica as categorias em variáveis binparias. Considere a mesma variável meio de transporte do exemplo anterior. Precisaríamos de duas variáveis aux1 e aux2. Com elas poderíamos fazer 00=carro, 01=moto, 10=taxi e 11=ônibus.
Para nosso problema, escolhemos a primeira técnica pois a segunda implicita uma ordem às categorias. No exemplo anterior, carro (00) é menor que moto (01) o que não faz sentido. Isso acaba acarretando distâncias diferentes entre pares de categorias. Por exemplo, a distância entre carro e ônibus (dois bits de diferença) é maior do que entre carro e moto (um bit de diferença), o que também não faz sentido. Com a primeira técnica, não existe ordenação implícita nas categorias.
Análise de Agrupamentos
A primeira etapa para realizar a análise de agrupamentos é definir uma função de distância para calcular a matriz de distâncias. A matriz de distâncias armazena a distância entre um registro do dataset e todos os outros registros. A principal forma de visualizar tal matriz é através do dataimage. Contudo, devido algumas limitações técnicas, não foi possível gerar o dataimage para esse problema, uma vez que estaríamos falando de uma matriz de 3,000,000 x 3,000,000 que exigiria mais memória do que tínhamos disponível.
Dentre todas funções de distância existentes, resolvemos utilizar a similaridade de Jaccard. Essa função permite o cálculo de distância considerando variáveis binárias, como é o caso do nosso dataset. A teoria por trás da Similaridade de Jaccard pode ser encontrada aqui. Para aplicar Jaccard aos dados, utilizamos a seguinte função do MATLAB: pdist(M,’jaccard’). O primeiro argumento é a matriz de dados M, o segundo argumento é a especificação da distância desejada, no caso Jaccard e retorna um vetor de distância associado aos dados.
A próxima etapa é a escolha do algoritmo de clusterização. Escolhemos aplicar o algoritmo mais popular, o K-means. A descrição do K-means pode ser encontrada aqui. O MATLAB também possui uma função que implementa esse algoritmo: kmeans(D,4). O primeiro argumento é o vetor de distâncias calculado no passo anterior, o segundo argumento é o número de grupos desejados (no nosso caso, 4) e retorna o agrupamento para cada registro.
Resultados
Abaixo, apresentamos a matriz de confusão gerada a partir do resultado da execução do K-means:
| Matriz de Confusão – Região x Grupo | ||||
|---|---|---|---|---|
| Grupo A | Grupo B | Grupo C | Grupo D | |
| Região 1 | 32622 | 25343 | 26367 | 32068 |
| Região 2 | 18779 | 16731 | 16959 | 20247 |
| Região 3 | 14626 | 11257 | 13867 | 16420 |
| Região 4 | 17523 | 14395 | 16014 | 20422 |
Nessa matriz, conseguimos visualizar quais grupos são mais representativos para determinadas regiões. Nesse caso, podemos observar que, de todos os registros pertencentes à região 1, por exemplo, 32262 registros também pertencem ao grupo A. De todos os valores obtidos para os diferentes grupos, esse foi o mais elevado em relação aos números de registros existentes dentro do mesmo grupo. Por isso, o grupo A mostrou-se a melhor opção para representar a região 1, para garantir que isso seja válido para cada região escolhemos a combinação que maximize as porcentagens. Os valores relativos para cada região podem ser analisados nas tabelas a seguir, as quais justificam a escolha de cada grupo para uma determinada região.
| Matriz de Confusão – Porcentagem de Acertos | ||||
|---|---|---|---|---|
| Grupo A | Grupo B | Grupo C | Grupo D | |
| Região 1 | P(1,A) | P(1,B) | P(1,C) | P(1,D) |
| Região 2 | P(2,A) | P(2,B) | P(2,C) | P(2,D) |
| Região 3 | P(3,A) | P(3,B) | P(3,C) | P(3,D) |
| Região 4 | P(4,A) | P(4,B) | P(4,C) | P(4,D) |
legenda:
- Ng: Número de registros do grupo
- Nr: Número de registros de uma mesma região
- P(r,g) = Nr/Ng
Os valores das porcentagens de acerto são apresentados na tabela abaixo:
| Matriz de Confusão – Porcentagem de Acerto | ||||
|---|---|---|---|---|
| Grupo A | Grupo B | Grupo C | Grupo D | |
| Região 1 | 0.27 | 0.22 | 0.23 | 0.28 |
| Região 2 | 0.25 | 0.23 | 0.23 | 0.28 |
| Região 3 | 0.26 | 0.20 | 0.25 | 0.29 |
| Região 4 | 0.25 | 0.21 | 0.23 | 0.30 |
Depois do agrupamento, cada registro foi alocado em um novo grupo. Com isso, pudemos ver qual grupo prevaleceu dentre os registros pertencentes a um mesmo estado. Alocamos, então, cada estado ao grupo prevalente e, considerando um grupo como uma região, obtivemos a seguinte divisão regional:
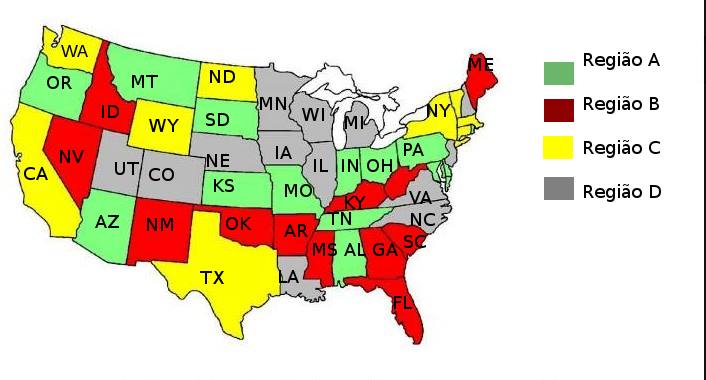
Devido a sua natureza e a diferentes pontos de inicialização, a cada execução do k-means, novos grupos são obtidos. Para comparar os resultados com a variável região sempre de maneira coerente, decidimos identificar os grupos de acordo com seu tamanho. Ou seja, diferente dos títulos usados nas tabelas anteriores, mesmos grupos de diferentes iterações possuem número de registro equivalente. Com isso, pudemos executar diversas instâncias do K-means e observar seus resultados.
Embora tenhamos escolhido, para cada grupo, a melhor classe que ele representa (na primeira execução), pode-se verificar que esse agrupamento foi muito ruim, com acurácia de 0.28, pouquíssimo melhor que a própria média. Portanto esses valores servem para demonstrar que, como esperado, as delimitações geográficas nos EUA não são mais uma boa forma de divisão sócio-econômica, apesar disso já ter sido uma realidade no passado e ter sido a motivação dessa divisão em regiões feita através do CENSO.
Conclusões
O resultado encontrado foi bem diferente da divisão regional atual dos Estados Unidos. Isso pode ter ocorrido por diversos motivos: como alguma falha durante o processo de mineração de dados, como também o resultado pode estar correto, já que fatores geográficos e culturais não foram considerados na análise dos dados (os dados cobrem somente as características socio-econômicas da população). A mudança das características da população com o passar dos anos também pode justificar o resultado diferente encontrado.
Apesar desse agrupamento de regiões não ter se mostrado muito efetivo já que os estados são bem parecidos em várias questões socioeconômicas, acreditamos que esse projeto atingiu seu propósito e ainda mostramos uma alternativa de divisão um pouco melhor. Além disso, tivemos a oportunidade de aprender e aplicar inúmeras técnicas de data mining , tivemos que tomar inúmeras decisões importantes baseadas em critérios técnicos e claro, enfrentamos diversas dificuldades técnicas, tecnológicas, e imprevistos, mas conseguimos superá-los e atingir um resultado satisfatório. Portanto, acreditamos que atingimos nossos objetivos tanto do projeto quanto de aprendizado.
Autores:
- Guilherme Iecker Ricardo
- Lyang Higa Cano
- Priscila da Silva Lima

Comentários