
Autores: Jônathan Elias Sousa da Costa e Renan Basílio
1: Introdução
O tema abordado neste trabalho é a popularidade de uma notícia publicada online, medida em quantidade de vezes que a mesma foi compartilhada por seus leitores. Para este propósito, foi utilizado como referência o dataset Online News Popularity[3], dataset este constituído por artigos publicados pelo site de notícias Mashable[4] durante o período de 2013 a 2015.
Note que como o dataset se refere a apenas um site, este tenderá a produzir resultados válidos apenas ao mesmo, potencialmente não sendo aplicável a outros sites de notícias que não compartilhem os mesmos nichos de usuários com o site em questão. Ainda assim é nossa opinião que os resultados produzidos pela análise deste tenham utilidade, ainda que exclusiva ao site que o produziu.
Este trabalho foi realizado para a disciplina COC361 – Inteligência Computacional, ministrada pelo professor Alexandre Evsukoff, no segundo período de 2017 com o objetivo de aplicar conhecimentos adquiridos a um problema do mundo real.
2: Objetivo
O objetivo deste trabalho é:
- Através da solução de um problema de classificação, prever se um artigo será ou não popular (definido, respectivamente, por número de shares maior ou menor que 1400) em função de suas características.
3: As Tecnologias
O trabalho foi realizado utilizando o software de mineração de dados KNIME. Elaboramos um único workflow para todo o projeto (vide Figura 1), reunindo variados nodes em grupos, de acordo com a tarefa computacional a ser realizada. Para algumas tarefas foram necessários sub-workflows (ex: pré-processamento, vide Figura 2).

Figura 1: Screenshot do workflow deste trabalho no KNIME.

Figura 2: Screenshot do sub-workflow de pré-processamento.
O computador do 2º integrante contava com um processador Core i7 de 2ª geração (4 núcleos físicos + 4 lógicos) e 8GB de RAM. O computador do 1º integrante contava com um processador Core i5 de 3ª geração (2 núcleos físicos + 2 lógicos) e 6GB de RAM. Em ambos o KNIME foi utilizado sob sistema operacional Windows 10.
4: Apresentação dos Dados
O dataset apresenta 39797 registros e 61 variáveis, uma das quais serve apenas para sua indexação (a URL do artigo).
O dataset não possui valores ausentes e todas as suas variáveis são números inteiros ou reais, como o dia da semana em que um artigo foi publicado já tendo sido vetorizadas em conjuntos de variáveis binárias. Desta forma não foi necessário fazer pré-processamento dos dados presentes no dataset.
A tabela no Apêndice 2 enumera as variáveis e fornece estatísticas básicas sobre as mesmas.
5: Pré-Processamento
5.1: Definição das Classes
Antes de qualquer coisa, como pretendemos resolver um problema de classificação sobre um dataset que apresenta valores numéricos, foi necessário definir as classes a partir dos mesmos. Para fazer essa separação, utilizamos os critérios definidos pelo mashable[3], site que forneceu o dataset. Esse critério define que um artigo é considerado popular quando é compartilhado mais do que 1400 vezes.
A Figura 3 demonstra a distribuição dos registros nas classes após essa separação. Note que este critério divide o dataset de uma forma bem balanceada, sendo 52% dos registros classificados como populares e os 48% restantes sendo impopulares.

Figura 3: Distribuição das Classes
5.2: Desvetorização
Primeiramente, foi feita a desvetorização das variáveis binárias do dataset, que representavam o dia da semana no qual o artigo foi publicado e a seção do site na qual tal publicação ocorreu (e.g. Tecnologia, Negócios, etc.). A Tabela 1 demonstra as variáveis finais e o conjunto de variáveis utilizadas para formar estas.
| weekday | weekday _is_monday
weekday_is_tuesday weekday_is_wednesday weekday_is_thursday weekday_is_friday weekday_is_saturday weekday_is_sunday is_weekend |
| data_channel | data_channel_is_business
data_channel_is_entertainment data_channel_is_lifestyle data_channel_is_socmed data_channel_is_technology data_channel_is_world |
Tabela 1: Features desvetorizadas.
5.3: Preenchimento de Valores Ausentes
Essa etapa se demonstrou difícil devido ao fato de que os valores ausentes no dataset não estavam simplesmente ausentes, mas constavam como apresentando valor zero em métricas que podiam, de fato, assumir este valor.
No entanto, a desvetorização das variáveis binárias permitiu detectar de fato valores que se encontravam ausentes nas mesmas. Esses valores ausentes ocorrem quando os valores de todas as colunas pertencentes a um conjunto desvetorizado possuem seus valores em zero.
Tendo identificado esses valores ausentes, foi possível fazer observações sobre os mesmos.
Primeiramente, para a variável weekday, foi observado que o dataset se encontra ordenado pela ordem de publicação dos artigos. Além disso, os valores ausentes se encontram em geral isolados ou em grupos pequenos. A partir destas observações foi decidido que utilizar o valor da variável no registro anterior seria uma forma boa de se preencher esses valores, já que a única possibilidade de erro ocorreria caso o registro com valor ausente tenha sido o primeiro publicado em um determinado dia.
Em relação à variável data_channel, uma observação que permitisse preencher os valores ausentes com alto nível de certeza como no caso anterior não foi possível. No entanto, observamos que a classe world, onde notícias internacionais são publicadas, continha um número consideravelmente maior de publicações que as demais. Assim, decidimos que a melhor política seria atribuir registros com valores ausentes a esta classe, sob o entendimento de que poucos registros incorretos inseridos nesta não viriam a atrapalhar tanto o model.
5.4: Normalização e Remoção de Outliers
A segunda etapa no pré processamento dos dados foi a normalização dos mesmos. A normalização foi feita através do z-score, com média em 0 e desvio padrão em 1, para as variáveis que não estavam já normalizadas no dataset.
As variáveis que não foram normalizadas eram ou relativas às demais (por exemplo, uma refletia o sentimento de um artigo em relação a todos os artigos publicados no site até o momento de sua publicação) e já normalizadas por característica própria da métrica, ou eram variáveis nominais e portanto intrinsecamente não normalizáveis.
Feita a normalização, foi feita a remoção de outliers. A remoção destes foi feita a partir de um filtro simples, onde para cada variável consideramos um intervalo de confiança de 99,8%, ou seja, para cada valor normalizado mantemos somente aqueles que estivessem no conjunto [-3, 3].
Ao fim, percebemos que esta tenha sido uma decisão potencialmente ruim. Como o teste foi feito individualmente para cada variável, foram removidos diversos registros que eram outliers em uma ou poucas variáveis. Esse filtro demasiadamente sensível resultou na remoção de cerca de 8000 registros, ou aproximadamente 21% do dataset, o que pode ter de fato vindo a prejudicar o modelo final.
A Figura 4 apresenta o boxplot dos dados após estas operações.

Figura 4: Boxplot
Note que as variáveis relativas também não tiveram seus outliers removidos. Essa foi uma escolha nossa devido ao interesse nosso quanto ao efeito de artigos consideravelmente diferentes dos demais em sua popularidade.
5.5: Remoção de Variáveis
Por fim, fizemos a remoção das variáveis que não seriam utilizadas pois não representavam uma métrica significativa para o estudo.
Primeiramente, a variável timedelta, que representa o tempo decorrido entre a publicação de um artigo e o imediatamente anterior, foi julgada não significativa pois engloba todas as seções do site. Por exemplo, o efeito da publicação de um artigo na seção de tecnologia do site não apresenta relação alguma com a publicação do próximo artigo na seção de política, e portanto a métrica não teria valor para a predição da popularidade deste.
Segundo, ao desenhar os histogramas, foi observado que as variáveis n_nonstop_words e n_unique_tokens, que representam o percentual de palavras que não estão localizadas no fim de uma frase (Figura 5) e o percentual de palavras únicas do título respectivamente. Essa métrica se apresentou quase constante, com variância insignificante para o propósito da resolução do problema, e portanto foi descartada.

Figura 5: Histograma da feature n_nonstop_words, com valor quase constante; a variação ocorre depois da sexta casa decimal.
Por fim, foi feita a análise da matriz de correlação (Figura 6). Foi observada uma correlação negativa de 100% entre as variáveis rate_positive_words e rate_negative_word, que representam, respectivamente, o percentual das palavras que apresentam sentimento positivo e negativo. Esta correlação se torna óbvia quando considerado o fato de que o classificador utilizado para determinar os sentimentos das palavras não possui o conceito de palavras neutras, sendo as variáveis então complementares. A correlação está evidenciada na Figura 7.
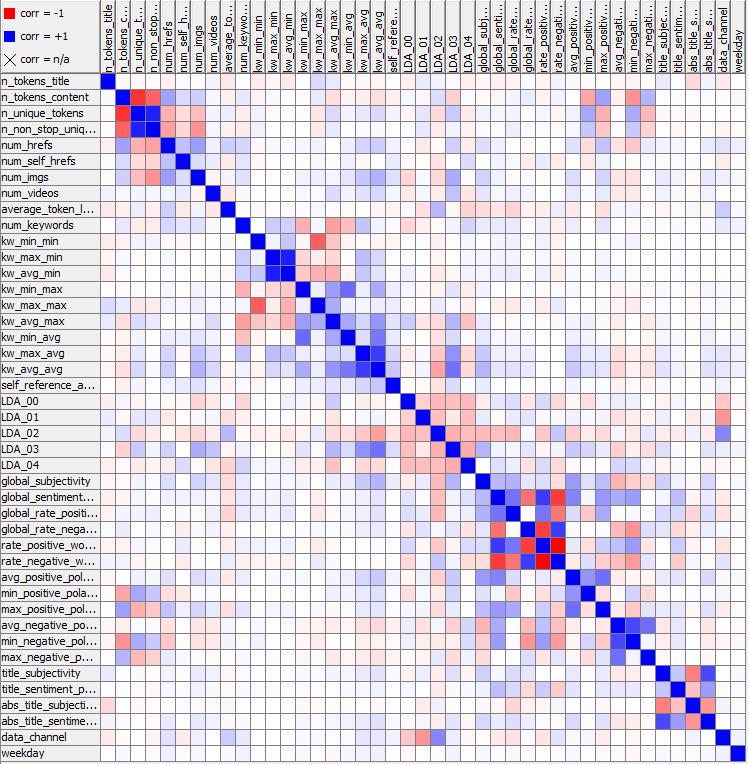
Figura 6: A matriz de correlação.

Figura 7: A cluster de sentimento sobre conteúdo da matriz de correlação.
Uma observação interessante pode ser feita a partir da figura 8; as variáveis title_sentiment_polarity e abs_title_sentiment_polarity apresentam uma correlação não linear – a segunda representa o valor absoluto da primeira. No entanto, embora sejam correlacionadas, ambas permaneceram no modelo, visto que tentativas de remoção de uma delas em todas as tentativas piorou a performance do modelo.

Figura 8: A cluster de sentimento sobre o título da matriz de correlação.
As últimas correlações fortes observada no modelo ocorrem na cluster de título, mas chegam apenas a 80% entre as variáveis n_unique_tokens e n_tokens_content, e n_nonstop_unique_tokens e n_unique_tokens. Essas correlações, no entanto, não proveem de características intrinsecamente correlacionadas. No caso do primeiro par, não existe relação intrínseca entre o número de palavras no título e o número de palavras no corpo do artigo, e, no caso do segundo par, títulos de artigo 80% das vezes possuem apenas um único fim de frase (stopword).
6: Metodologia
Para cada classificador, avaliamos sua performance por conhecidas métricas de desempenho – vistas em aula – obtidas em validação cruzada de 10 ciclos através do método k-fold, que consiste no particionamento do dataset em k partes iguais (no caso, k = 10), k-1 das quais (no caso, 9) são utilizadas para o treinamento do classificador (conjunto de treino), com a k-ésima (no caso, décima) parte sendo utilizada para sua validação (conjunto de teste). Em cada ciclo, obtemos métricas parciais de desempenho, e por fim, consideramos como resultado final a média dos resultados parciais, na esperança de obtermos métricas mais acuradas quanto à performance do modelo quando aplicado sobre um conjunto de dados “real” [5].
A amostragem utilizada para a seleção do conjunto de testes foi aleatória. Isso significa que cada conjunto de testes reuniu 10% dos registros do dataset, selecionados aleatoriamente, sem repetição (tanto dentro da mesma iteração quanto globalmente nas 10 execuções do modelo em validação cruzada).
A classe Popular foi utilizada como classe positiva ou de referência nas métricas de avaliação.
Seguem abaixo resumos das definições de métricas de avaliação de desempenho a serem consideradas neste trabalho:
- Acurácia (ACC): taxa global de classificação correta. Determinada pela razão entre a quantidade de verdadeiros e a quantidade de entradas.

- Precisão (PRE): quantifica a capacidade de predição do modelo. Responde a pergunta: quantos elementos selecionados são relevantes?
- Recall (REC, revocação): quantifica a capacidade de correto reconhecimento do modelo. Responde a pergunta: quantos elementos relevantes foram selecionados?
- Medida-F (F1): precisão e recall combinados em uma medida uniformemente ponderada: é a média harmônica dos dois, ou seja, quadrado da média geométrica dividido pela média aritmética.

- Espaço ROC: espaço gerado pelas dimensões “sensibilidade” vs “1 – especificidade”, ou seja, taxa de verdadeiros positivos vs taxa de falsos positivos.
- Área sobre a curva ROC (AUC): uma das medidas mais importantes, revela o poder de discriminação do classificador, independente do threshold selecionado. Pode ser calculada (aproximada) pela Média aritmética entre recall + especificidade para ponto que minimiza distância até (0,1) = taxa máxima de verdadeiro positivo e mínima de falso positivo. Quantifica a probabilidade do classificador predizer corretamente a classe para uma entrada.
7: Classificadores Simples
7.1: Regressão Logística
Aplicamos primeiramente o modelo de Regressão Logística, abordado em detalhes já nas primeiras semanas do curso de Aprendizado de Máquina do Prof. Andrew Ng, no Coursera.[7]
O modelo de regressão logística adapta técnicas de regressão linear para a determinação de uma superfície de separação entre duas classes (numericamente 0 ou 1, classificação binária) discriminada por uma curva sigmóide – ou ainda, hipótese logística, regida pela equação da Figura 9 – regularizada por uma função custo com fatores exponenciais (vide Figura 10) que penalizam severamente o modelo em caso de erros na predição. Isto ocorre para que a curva possa ser melhor ajustada ao modelo, evitando o overfitting. [7]

Figura 9: Lei da (Função) Hipótese sigmóide, ou logística.

Figura 10: Lei da Função Custo para a Regressão Logística
Como podemos ver na Figura 10, se a saída conhecida de uma entrada de treino é  = 0, o primeiro termo do somatório é descartado. Neste caso, como podemos ver no segundo termo, se = 0 mas o modelo retorna predição
= 0, o primeiro termo do somatório é descartado. Neste caso, como podemos ver no segundo termo, se = 0 mas o modelo retorna predição  = 1, então o custo da predição para esta entrada será altíssimo, uma vez que log(1-1)=log(0)=∞. Situação semelhante ocorre quando
= 1, então o custo da predição para esta entrada será altíssimo, uma vez que log(1-1)=log(0)=∞. Situação semelhante ocorre quando  = 1, porém = 0. Esta função de custo bem caracterizada nos permite otimização através da determinação dos parâmetros teta que minimizam o custo (erro entre classe predita e classe “verdadeira”). Para esta otimização, utilizamos o método do gradiente, que consiste na determinação de um mínimo local de uma função no Rn a partir de um ponto, através de “descidas” iteradas (tamanho do passo escolhido arbitrariamente ou algoritmicamente por outras técnicas) na direção de maior minimização do valor da função no ponto (gradiente negativo). Poderíamos também utilizar o método das Equações Normais para otimização dos parâmetros téta, com a vantagem de podermos calcular de forma vetorizada e, portanto, instantânea, valores ótimos aproximados para cada parâmetro téta.
= 1, porém = 0. Esta função de custo bem caracterizada nos permite otimização através da determinação dos parâmetros teta que minimizam o custo (erro entre classe predita e classe “verdadeira”). Para esta otimização, utilizamos o método do gradiente, que consiste na determinação de um mínimo local de uma função no Rn a partir de um ponto, através de “descidas” iteradas (tamanho do passo escolhido arbitrariamente ou algoritmicamente por outras técnicas) na direção de maior minimização do valor da função no ponto (gradiente negativo). Poderíamos também utilizar o método das Equações Normais para otimização dos parâmetros téta, com a vantagem de podermos calcular de forma vetorizada e, portanto, instantânea, valores ótimos aproximados para cada parâmetro téta.
Nosso dataset apresenta mais de 30.000 registros (n), de forma que uma solução analítica por Equações Normais torna-se impraticável (pois envolverá inversão de matriz n x n). Optamos então por utilizar o método do gradiente (GD), mais especificamente o método estocástico do gradiente (SGD): ao invés de derivar a função custo em relação a cada téta para cada um dos 30.000 registros, a cada iteração, aproveitamos o tamanho do dataset e a presumida independência estatística entre os registros para utilizar apenas um registro aleatório a cada iteração na otimização dos parâmetros téta (operação computacionalmente mais eficiente, pois é mais fácil de ser vetorizada). Logo, esperamos uma descida bem mais rápida, mas menos precisa do que o GD comum. O SGD retorna um “quase”-mínimo em um menor tempo de treino, embora geralmente demande mais iterações. [6] Aplicamos o SGD com taxa de aprendizagem (alfa) = 0.1. A convergência foi alcançada com 2000 epochs (iterações) para uma tolerância = 1E10-4. Entendemos aqui por convergência a finalização da otimização dos tétas e por pesos os lambdas de regularização.
Os testes deste modelo foram realizados para cada um dos três métodos de regularização de parâmetros oferecidos pelo KNIME:
- Uniforme: equivale a aplicar o modelo sem nenhuma regularização. Assumimos pesos iguais para os parâmetros téta.
- Gauss: assumimos pesos de parâmetros téta seguindo distribuição normal.
- Laplace: assumimos pesos de parâmetros téta seguindo distribuição exponencial
O valor de corte para função discriminante utilizado internamente pelo modelo para fornecer a classificação final foi = 0.5.
| Gauss (var. 1)
Pop. – Impop. |
Laplace (var. 1)
Pop. – Impop. |
Uniforme
Pop. – Impop. |
|
| Precisão | 67,0 % – 64,7 % | 67,1 % – 64,7 % | 67,0 % – 64,7 % |
| Recall (Revocação) | 67,6 % – 64,1 % | 67,7 % – 64,1 % | 67,6 % – 64,1 % |
| Medida F (F1) | 67,3 % – 64,4 % | 67,4 % – 64,4 % | 67,3 % – 64,4 % |
| Acurácia | 65,9 % | 66,0 % | 65,9 % |
| AUC | 71,0 % | 71,0 % | 71,1 % |
| Ordem de grandeza do tempo total de execução (10 ciclos): unidades de minutos | |||
Tabela 2: Desempenho da classificação por Regressão Logística
Analisando o resultado da Tabela 2, podemos concluir:
- Relação quantitativa entre precisão e recall entre classes revela balanceamento entre as classes.
- AUC > 0.7. Resultado satisfatório (razoável).
- Distribuição a priori de parâmetros praticamente não influenciou na regularização. Concluímos que a curva não “overfita” mesmo sem regularização, o que é difícil de ocorrer, mas possível. O dataset pode ter sido recortado de alguma forma para alcançar esta característica, antes de ser publicado.
- Capacidade de discriminar se assemelhou à capacidade de predizer que igualou a capacidade de acertar.
7.2: K-Vizinhos Mais Próximos (KNN)
Em seguida optamos por tentar aplicar um classificador disponível no KNIME, abordado no artigo que acompanha o dataset, mas não abordado em aula. Por certo, o KNN é um dos mais simples classificadores existentes, dado que ele é não-paramétrico, ou seja, não necessita que dados apresentem distribuição específica, p ex: gaussiana ou exponencial, e é baseado em instância, ou seja, não gera um modelo. O KNN apenas memoriza os registros de treino (armazena todos na memória), que serão usados no momento da predição: classe predita é aquela mais frequente nos k registros mais próximos (Figura 11) [8].

Figura 11: O funcionamento do KNN. Os k = 7 registros mais próximos da entrada são analisados e a classe mais frequente entre estes é escolhida.[8]
Para escolha do hiperparâmetro k utilizamos a regra da literatura [10]: k = raiz quadrada do número de amostras a serem treinadas ~ 167 no nosso caso (importante ser ímpar para evitar empates). Distância utilizada foi a Euclidiana.
| K = 167
Pop. – Impop. |
Artigo, K = {1, 3, 5, 10, 20}
Pop. |
|
| Precisão | 67,6 % – 62,6 % | 66,0 % |
| Recall (Revocação) | 62,6 % – 67,6 % | 55,0 % |
| Medida F (F1) | 65,0 % – 65,0 % | 60,0 % |
| Acurácia | 65,0 % | 62,0 % |
| AUC | 70,7 % | 67,0 % |
| Ordem de grandeza do tempo total de execução (10 ciclos): unidades de minutos |
||
Tabela 3: Desempenho da classificação por Regressão Logística
*Artigo apresentou o melhor resultado obtido dentre as execuções com estes valores para o hiperparâmetro n (técnica grid-search), com validação cruzada holdout (70% treino e 30% teste).
Artigo buscou melhor k entre conjunto enunciado, em grid search, Embora não possamos comparar diretamente devido ao nosso pré-processamento e à nossa validação cruzada k-fold, alcançamos melhores resultados no geral. Artigo não especificou critério para a escolha das quantidades do grid-search.
Analisando o resultado da Tabela 3, podemos constatar:
- Nosso AUC > 0.7. Resultado (modelo) satisfatório (razoável).
- AUC do artigo < 0.7. Ruim.
- Resultado razoável indica balanceamento no dataset.
- Resultado também indica razoável estruturação local do dataset, ou seja, os vizinhos podem ser considerados quase sempre informativos, mesmo que insatisfatoriamente.
7.3: Bayesiano Simples
Em seguida aplicamos um classificador bem visto em aula, o bayesiano simples. Neste modelo as variáveis de entrada são consideradas descorrelacionadas (o que é uma premissa razoável segundo nossa matriz de correlação). Calculamos então a probabilidade, a posteriori ( P[Ci|x] ), de uma entrada pertencer a uma determinada classe, ao determinar a probabilidade condicional de dada entrada ( P[x|Ci] ) ponderada pela probabilidade a priori ( P[Ci] ) dada cada classe. P(x) é apenas um fator de padronização, relacionado à frequência da entrada x no dataset. A classe atribuída à entrada será aquela de maior probabilidade condicional. [1]

Embora o bayesiano simples seja um classificador intencionado para atributos nominais, consideramos atributos numéricos com distribuição normal para aplicar o algoritmo a todos os possíveis atributos. Tomamos, para este caso, a função densidade de probabilidade (PDF) como probabilidade condicional p(x|Ci).
Para atributos nominais calculamos a probabilidade condicional diretamente pela definição (vide Figura 12), pois podemos determinar a cardinalidade de conjuntos discretos, como por exemplo, o número de registros que possuem atributo Y com valor X e pertencentes à classe C . Para variáveis numéricas usamos a PDF do atributo Y aplicada no valor X com média e variância respectivas à classe C (vide Figura 13). Para esta dataset multivariado, na prática, a probabilidade condicional geral, dada uma classe, será determinada pelo produtório das probabilidades condicionais para cada atributo. [1]
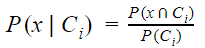
Figura 12: Probabilidade condicional para 1 atributo nominal.

Figura 13:Probabilidade condicional para 1 atributo numérico. Mi e sigma são obtidos para cada classe após a normalização do atributo.

Figura 14: Tabela de Classe Real vs. Classe Predita
| Próprio
Pop. – Impop. |
Artigo
Pop. |
|
| Precisão | 60 % – 69,1 % | 68,0 % |
| Recall (Revocação) | 83,5 % – 39,9 % | 49,0 % |
| Medida F (F1) | 65,0 % – 65,0 % | 57,0 % |
| Acurácia | 62,5 % | 62,0 % |
| AUC | 67,7 % | 65,0 % |
| Ordem de grandeza do tempo total de execução (10 ciclos): unidades de minutos | ||
Tabela 4: Desempenho da classificação por Regressão Logística
Analisando o resultado da Tabela 4, podemos concluir:
- Recall de 83,5% confere: 13485 VP de populares preditos de um total de 16147 populares de fato (vide Figura 14).
- Ambos os AUC entretanto, implicam em modelos “ruins”.
- Tendência a favor da classe popular.
- Comparando resultados “brutos” próprios e do artigo, concluímos que nosso pré-processamento, principalmente a normalização prévia de todos os atributos numéricos (com média nula), influenciou consideravelmente o desempenho deste classificador.
- Como o dataset é balanceado, produto das distribuições condicionais foi consideravelmente maior para a classe popular.
- Notamos que atributos isolados separam linearmente o problema em nível insatisfatório, mas aceitável, como kw_avg_avg (com ACC 0,6).
8: Ensambles
8.1: Random Forest
Testamos, em seguida, um classificador do tipo “Ensemble Learning”. Classificadores ensemble agregam e ponderam resultados das execuções de vários classificadores aplicados com parâmetros e\ou subsets diferentes. [12] Espera-se portanto, mais acurácia e poder de discriminação na predição por ensemble. Importante notar que o fato de reunir resultados de vários classificadores em uma única predição diferencia a avaliação de um classificador ensemble dos demais classificadores simples, não sendo “justo” compará-los diretamente, dado o custo computacional consideravelmente maior para efetuar a agregação de resultados.
O classificador Random Forest (RF) consiste na agregação do resultado de várias árvores de decisão – abreviada para DT, do inglês Decision Tree, não abordado em aula – aleatórias, aplicadas a diferentes subsets de registros e atributos. Para um problema de classificação, a RF agrega os resultados das variadas DTs, retornando como predição final a moda (classe mais frequentemente predita, vide Figura 9). O objetivo é o de reduzir a variância e possível overfitting da DT. [13]
Se as regras de decisão forem muito estritas, fazendo a DT fitar muito bem o conjunto de treino, certamente ocorrerá tendência a overfit. Em uma DT, dois processos podem ser executados para amenizar overfitting: pré-poda (interromper o crescimento da árvore antes de ela fitar perfeitamente o conjunto de treino) e pós-poda (deixar fitar e usar validação cruzada para otimizar acurácia no teste). [14]
O RF envolve a escolha de um hiperparâmetro: o número de árvores aleatórias a serem geradas. Concluímos que o aumento do número de árvores pode ser vantajoso enquanto redução de variância mostrar-se eficaz. A partir de certo ponto, as métricas de desempenho revelarão estagnação no poder de discriminação do modelo gerado (neste ponto alcançamos um número “bom” de árvores).
RF do KNIME gera muitas árvores de decisão de 1 nível (pré-poda severa).

Figura 15: Estrutura de uma Random Forest[15]

Figura 16: Amostras de árvores geradas pelo KNIME
| Próprio
n = 500 Pop. – Impop. |
Artigo,
n = {10, 20, 50, 100, 200, 400} Pop. |
|
| Precisão | 67,8 % – 67,0 % | 67,0 % |
| Recall (Revocação) | 70,9 % – 63,7 % | 71,0 % |
| Medida F (F1) | 69,4 % – 65,3 % | 69,0 % |
| Acurácia | 67,4 % | 67,0 % |
| AUC | 73,6 % | 73,0 % |
| Ordem de grandeza do tempo total de execução (10 ciclos): dezenas de minutos | ||
Tabela 5: Desempenho da classificação por Regressão Logística
*Artigo apresentou o melhor resultado obtido dentre as execuções com estes valores para o hiperparâmetro n (técnica grid-search), com validação cruzada holdout (70% treino e 30% teste).
Analisando o resultado da Tabela 5, podemos concluir:
- RF retornou o melhor poder de discriminação entre os classificadores testados.
- Nosso AUC > 0.7. Resultado (modelo) satisfatório (razoável), muito semelhante ao alcançado pelo artigo.
9: Redes Neurais
9.1: Perceptron de Múltiplas Camadas (MLP)
O primeiro modelo de rede neural que tentamos aplicar ao problema foi o Perceptron de Múltiplas Camadas. O perceptron é uma rede neural tradicional, que consiste em neurônios que definem, cada um, um par de funções a serem aplicadas às suas entradas. A primeira função, chamada função potencial, mapeia a entrada do neurônio em uma base na qual o problema seja separável, enquanto a segunda função, chamada função de ativação, determina se a entrada está na região positiva ou negativa dessa base. A Figura 17 representa a estrutura de um MLP com duas camadas.
O perceptron de múltiplas camadas possui como parâmetros ajustáveis o número de neurônios por camada e o número de camadas. Para efeito didático, escolhemos treinar modelos com 1, 2 ou 3 camadas, e 10 ou 20 neurônios por camada a fim de comparar o efeito do aumento dos mesmos na qualidade do modelo. A Tabela 6 apresenta os resultados obtidos.

Figura 17: Estrutura de um Perceptron de Duas Camadas
| 10 Neurônios por Camada
Pop. – Impop. |
20 Neurônios por Camada
Pop. – Impop. |
|
| 1 Camada | ||
| Precisão | 67,3% – 65,6% | 67,3% – 65,4% |
| Recall | 68,9% – 67,3% | 68,6% – 68,6% |
| Medida F (F1) | 68,1% – 64,7% | 67,9% – 64,7% |
| Acurácia | 66,5% | 66,4% |
| AUC | 71,9% | 72,1% |
| 2 Camadas | ||
| Precisão | 67,0% – 65,4% | 67,1% – 65,1% |
| Recall | 68,9% – 63,4% | 68,4% – 63,8% |
| Medida F (F1) | 67,9% – 64,4% | 67,7% – 64,4% |
| Acurácia | 66,2% | 66,2% |
| AUC | 71,8% | 71,8% |
| 3 Camadas | ||
| Precisão | 66,9% – 65,3% | 66,9% – 65,1% |
| Recall | 68,9% – 65,3% | 68,6% – 63,4% |
| Medida F (F1) | 67,9% – 64,2% | 67,7% – 64,2% |
| Acurácia | 66,1% | 66,1% |
| AUC | 71,6% | 71,6% |
Tabela 6: Resultados dos MLP em validação cruzada (10x).
Os resultados mostram uma ligeira diminuição da precisão e acurácia com o aumento do número de camadas, enquanto o valor das mesmas estatísticas permanece quase constante com o aumento do número de neurônios. Isso, em conjunto com a precisão e recall relativamente baixos, indica que até 3 operações sucessivas não foram capazes de levar os registros a uma base nos quais estes eram linearmente separáveis, indicativo de um modelo mais complexo ou até mesmo inseparável a partir das variáveis de entrada.
9.2: Rede Neural Probabilística (PNN)
A fim de explorar as opções de redes neurais disponíveis no KNIME, foi também treinada uma Rede Neural Probabilística (ou PNN, do inglês “Probabilistic Neural Network”).
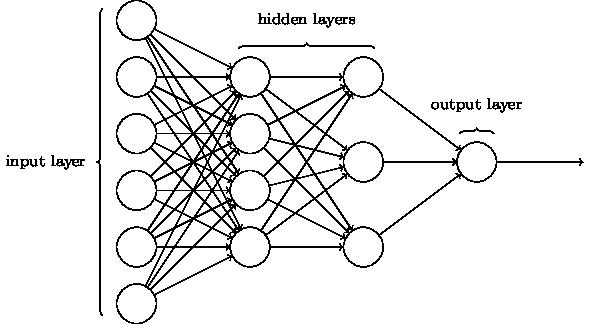
Figura 18: Estrutura de uma PNN
A PNN consiste em um modelo que procura fazer uma classificação baseada no reconhecimento de padrões que ocorrem no dataset de treinamento, e minimizando a probabilidade de classificação incorreta. A Figura 18 mostra a estrutura de uma PNN.
A primeira camada da PNN, chamada de Input Layer ou Camada de Entrada, consiste em um neurônio por variável de entrada. Esta camada faz, ainda, a normalização dos dados caso estes não estejam já normalizados.
A segunda camada, chamada de Pattern Layer ou Camada de Padrões, possui um neurônio por registro notável do conjunto de treinamento. Um registro notável é definido como aquele que atende a uma regra definida por dois valores, θ+ e θ–. Estes dois valores representam o raio máximo e mínimo de uma função de base radial utilizada para comparar o registro sendo avaliado com o centro do registro para o qual o neurônio foi treinado.
A terceira camada, chamada Summation Layer ou Camada de Soma, possui um neurônio para cada classe de cada variável alvo. Essa camada realiza a soma das distâncias válidas (regras ativadas) fornecidas pela camada anterior.
A quarta e última camada, chamada Output Layer ou Camada de Saída, possui um neurônio para cada variável de saída. Cada neurônio recebe a soma das distâncias produzidas pela camada anterior, escolhendo aquela de menor soma como a mais próxima dos padrões utilizados para o treinamento.
Essas características fazem da PNN um modelo robusto, que não é afetado por outliers. No entanto, por ser um classificador baseado fortemente nos registros de treinamento, produz um modelo que pode não ser aplicável a casos imprevistos. Além disso, como o modelo cria regras para cada entrada, este acaba ocupando um grande volume de memória.
Para efeito de teste, os valores de θ+ e θ– utilizados foram iguais, resultando em uma métrica onde a distância mínima entre duas regras quaisquer é igual a 2θ e só a regra mais próxima do registro é ativada. A Tabela 7 demonstra os resultados da validação cruzada PNNs treinadas utilizando os valores de θ determinados pelo grupo.
| θ = 0.01
Pop. – Impop. |
θ = 0.1
Pop. – Impop. |
θ = 0.5
Pop. – Impop. |
θ = 1.0
Pop. – Impop. |
|
| Precisão | 64,2% – 66,2% | 61,2% – 69,6% | 60,6% – 70,3% | 60,5% – 70,1% |
| Recall | 73,7% – 55,5% | 82,3% – 43,6% | 84,0% – 41,0% | 83,8% – 41,0% |
| Medida F (F1) | 68,6% – 60,4% | 70,2% – 53,6% | 70,4% – 51,8% | 70,3% – 51,7% |
| Acurácia | 65% | 63,7% | 63,3% | 63,2% |
| AUC | 70,4% | 70,7% | 70,6% | 70,6% |
| Número de Regras | 15047 | 15181 | 26682 | 26735 |
Tabela 7: Resultados das PNNs em validação cruzada (10x).
Os resultados são notavelmente semelhantes aos do classificador bayesiano, sendo válidas as mesmas observações feitas para o mesmo. O que é interessante de se observar aqui é o efeito da redução do valor de θ no número de regras criadas na camada de padrões; com valores elevados do mesmo regras foram criadas para todos os registros de entrada, enquanto para valores menores menos regras foram criadas. Esse efeito se deve ao fato de que valores de θ menores permitem a formação de regiões contíguas em um conjunto fortemente inseparável, das quais regras podem ser eliminadas por estarem completamente envolvidas por outras de mesma classe. Com valores maiores, a colisão de regras se torna mais provável, devido a regras opostas próximas de um conjunto encobrindo parte do mesmo.
10: Conclusões
| Recall | ACC | AUC | |
| Regressão Logística | 67,6 % | 65,9 % | 71,0 % |
| kNN | 62,6 % | 65,0 % | 70,7 % |
| Bayesiano Simples | 83,5 % | 62,5 % | 67,7 % |
| Random Forest | 70,9 % | 67,4 % | 73,6 % |
| Perceptron de Múltiplas Camadas (MLP) | 68,6% | 66,4% | 72,1% |
| Rede Neural Probabilística (PNN) | 82,3% | 63,7% | 70,7% |
Tabela 8: Resumo dos resultados de todos os classificadores
Julgamos as classificações ruins, devido ao poder de discriminação apenas razoável (como podemos ver na Tabela 8, AUC permaneceu em torno de 0.7 para todos os classificadores). Ressaltamos, porém, que esta limitação aparenta ser característica do dataset, dado que nenhum classificador se sobressaiu neste quesito.
Registramos o melhor recall nos classificadores Bayesiano Simples e PNN (REC 83%) e o melhor poder de discriminação no classificador Random Forest (AUC 74%).
Para o nosso caso, é mais importante o acerto na predição da classe popular, ou seja, queremos um maior recall para esta classe. Sendo assim, concluímos que o Bayesiano Simples é a melhor escolha de classificador em termos de custo computacional, consumindo consideravelmente menos tempo de processamento e espaço em memória para chegar a resultados satisfatórios (REC 83% e AUC 68%). PNN é melhor em termos gerais (REC 82% e AUC 71%).
Concluímos que problema não está sendo bem descrito pelo dataset: temos informações estatísticas sobre os artigos, mas nenhuma informação sobre o conteúdo dos mesmos. Métricas mais descritivas sobre o artigo poderiam melhorar a medição, por exemplo, atributos que revelassem:
- Quão atual é o tema.
- Quão bem divulgado foi o mesmo (Manchete na página principal? Mídia social?).
- Conteúdo do artigo
11: Referências
- Evsukoff, A. Ensinando Máquinas, 2017.
- K. Fernandes, P. Vinagre and P. Cortez. A Proactive Intelligent Decision Support System for Predicting the Popularity of Online News. Proceedings of the 17th EPIA 2015 – Portuguese Conference on Artificial Intelligence, September, Coimbra, Portugal.
- ___________. Online News Popularity Data Set. Disponível em <https://archive.ics.uci.edu/ml/datasets/online+news+popularity>. Acesso em 10/09/2017
- ___________. Mashable. Disponível em <http://mashable.com/>. Acesso em 10/09/2017.
- ___________. Cross-validation (statistics). Disponível em <https://en.wikipedia.org/wiki/Cross-validation_(statistics)>. Acesso em 18/11/2017.
- Ng, Andrew et al. Optimization: Stochastic Gradient Descent. Disponível em <http://ufldl.stanford.edu/tutorial/supervised/OptimizationStochasticGradientDescent/>. Acesso em 18/11/2017.
- Ng, Andrew. Cost Function. Disponível em <https://www.coursera.org/learn/machine-learning/supplement/bgEt4/cost-function>. Acesso em 18/11/2017.
- Pacheco, André. K vizinhos mais próximos – KNN. Disponível em: <http://www.computacaointeligente.com.br/algoritmos/knn-k-vizinhos-mais-proximos/>. Acesso em 18/11/2017.
- ___________. Logistic regression. Disponível em: <https://en.wikipedia.org/wiki/Logistic_regression>. Acesso em 18/11/2017.
- Duda, R., Hart, P. and Stork, D. Pattern classification. 1973. New York, N.Y. etc.: Wiley.
- Amo, Sandra. Curso de Data Mining. Disponível em < http://www.deamo.prof.ufu.br/arquivos/Aula11N.pdf>. Acesso em 18/11/2017.
- ___________. Ensemble learning. Disponível em <https://en.wikipedia.org/wiki/Ensemble_learning>. Acesso em 18/11/2017.
- ___________. Random forest. Disponível em <https://en.wikipedia.org/wiki/Random_forest>. Acesso em 18/11/2017.
- Sayad, Saed. Decision Tree – Overfitting. Disponível em <http://www.saedsayad.com/decision_tree_overfitting.htm>. Acesso em 18/11/2017.
- Jagannath, Venkata. Random Forest Template for TIBCO Spotfire® – Wiki page. Disponível em <https://community.tibco.com/wiki/random-forest-template-tibco-spotfirer-wiki-page>. Acesso em 18/11/2017.
Apêndice 1: Descrições das variáveis utilizadas
| Variável | Descrição |
| url | A URL do artigo. |
| n_tokens_title | O número de palavras no título. |
| n_tokens_content | O número de palavras no artigo. |
| n_unique_tokens | A frequência de palavras no artigo que não são repetições. |
| n_non_stop_words | A frequência de palavras que não precedem o fim de uma frase. |
| n_non_stop_unique_tokens | A frequência de plalavras que não são repetições e que finalizam uma frase. |
| num_hrefs | O número de links no artigo. |
| num_self_hrefs | O número de links a outras páginas do próprio site no artigo. |
| num_imgs | O número de imagens no artigo. |
| num_videos | O número de vídeos no artigo. |
| average_token_length | O comprimento (número de letras) médio das palavras no artigo. |
| num_keywords | O número de palavras chaves na metadata do artigo. |
| kw_min_min | A popularidade mínima da palavra chave menos popular. |
| kw_max_min | A popularidade máxima da palavra chave menos popular. |
| kw_avg_min | A popularidade média da palavra chave menos popular. |
| kw_min_max | A popularidade mínima da palavra chave mais popular. |
| kw_max_max | A popularidade máxima da palavra chave mais popular. |
| kw_avg_max | A popularidade média da palavra chave mais popular. |
| kw_min_avg | A popularidade mínima das palavras chave (em média). |
| kw_max_avg | A popularidade máxima das palavras chave (em média). |
| kw_avg_avg | A popularidade média das palavras chave (em média). |
| self_refs_min_shares | A popularidade do artigo menos popular linkado. |
| self_refs_max_shares | A popularidade do artigo mais popular linkado. |
| self_refs_avg_sharess | A popularidade média dos artigos linkado. |
| LDA_00 | Proximidade com tópico 0 do LDA |
| LDA_01 | Proximidade com tópico 1 do LDA |
| LDA_02 | Proximidade com tópico 2 do LDA |
| LDA_03 | Proximidade com tópico 3 do LDA |
| LDA_04 | Proximidade com tópico 4 do LDA |
| global_subjectivity | Subjetividade do tópico do artigo. |
| global_sentiment_polarity | O quanto as opiniões sobre o tópico diferem (polaridade do tópico) |
| global_rate_positive_words | A frequência de palavras “positivas” no artigo. |
| global_rate_negative_words | A frequência de palavras “negativas” no artigo. |
| rate_positive_words | A taxa de palavras positivas em relação às demais no artigo. |
| rate_negative_words | A taxa de palavras negativas em relação às demais no artigo. |
| avg_positive_polarity | A polaridade média das palavras positivas no artigo. |
| min_positive_polarity | A polaridade mínima das palavras positivas no artigo. |
| max_positive_polarity | A polaridade máxima das palavras positivas no artigo. |
| avg_negative_polarity | A polaridade média das palavras negativas no artigo. |
| min_negative_polarity | A polaridade mínima das palavras negativas no artigo. |
| max_negative_polarity | A polaridade máxima das palavras negativas no artigo. |
| title_subjectivity | A subjetividade do título do artigo. |
| title_sentiment_polarity | A polaridade do título do artigo. |
| abs_title_subjectivity | A subjetividade absoluta do título do artigo. |
| abs_title_sentiment_polarity | A polaridade absoluta do título do artigo. |
| shares | O número de vezes que o artigo foi compartilhado. |
Apêndice 2: Estatísticas básicas das variáveis utilizadas
| Variável | Mínimo | Máximo | Média | Mediana | Desvio Padrão | Variância |
| url | N/A | N/A | N/A | N/A | N/A | N/A |
| n_tokens_title | 5 | 16 | 10.3984179 | 10 | 2.073508455 | 4.299437314 |
| n_tokens_content | 24 | 1956 | 507.1242202 | 407 | 342.4846422 | 117295.7302 |
| n_unique_tokens | 0.18181818 | 0.99999996 | 0.552257046 | 0.547169808 | 0.096383116 | 0.009289705 |
| n_non_stop_words | 0.99999992 | 0.99999999 | 0.999999994 | 0.999999995 | 3.91E-09 | 1.53E-17 |
| n_non_stop_unique_tokens | 0.25311203 | 0.99999998 | 0.700513376 | 0.698113204 | 0.092471902 | 0.008551052 |
| num_hrefs | 0 | 44 | 9.857579266 | 8 | 7.570046183 | 57.30559921 |
| num_self_hrefs | 0 | 14 | 2.981831629 | 3 | 2.403855895 | 5.778523165 |
| num_imgs | 0 | 29 | 3.611582738 | 1 | 5.425542833 | 29.43651503 |
| num_videos | 0 | 13 | 0.691812978 | 0 | 1.686897421 | 2.845622908 |
| average_token_length | 3.6 | 6.81675392 | 4.690690535 | 4.681222707 | 0.2790511747 | 0.07786955808 |
| num_keywords | 2 | 10 | 7.238311145 | 7 | 1.88437072 | 3.550853012 |
| kw_min_min | -1 | 217 | 10.8436877 | -1 | 45.54986086 | 2074.789824 |
| kw_max_min | 0 | 12700 | 929.3437475 | 657 | 1098.385819 | 1206451.408 |
| kw_avg_min | -1 | 2170.25 | 266.7710562 | 221.6833333 | 214.1813812 | 45873.66405 |
| kw_min_max | 0 | 161600 | 8350.347546 | 1400 | 18754.13129 | 3.52E+08 |
| kw_max_max | 111300 | 843300 | 809625.1431 | 843300 | 75935.00867 | 5.77E+09 |
| kw_avg_max | 31670 | 664120 | 267293.7084 | 249711.1111 | 107649.483 | 1.16E+10 |
| kw_min_avg | -1 | 3610.12497 | 1090.794788 | 1017.522727 | 1104.857202 | 1220709.437 |
| kw_max_avg | 2833.70667 | 23949.3076 | 5155.640087 | 4320.596367 | 2368.590301 | 5610220.014 |
| kw_avg_avg | 488.982313 | 7082.84934 | 3044.162121 | 2848.815847 | 921.6837276 | 849500.8938 |
| self_refs_min_shares | 0 | 62900 | 3171.198924 | 1300 | 6412.095928 | 4.11E+07 |
| self_refs_max_shares | 0 | 128900 | 7086.4169 | 2800 | 12594.35087 | 1.59E+08 |
| self_refs_avg_sharess | 0 | 77450 | 4780.86453 | 2233.333333 | 7786.257566 | 6.06E+07 |
| LDA_00 | 0.01818197 | 0.92699438 | 0.190979686 | 0.033394505 | 0.268107191 | 0.071881466 |
| LDA_01 | 0.01818195 | 0.91997615 | 0.140830635 | 0.033339875 | 0.221288161 | 0.048968450 |
| LDA_02 | 0.01818195 | 0.91999908 | 0.231465458 | 0.040060245 | 0.290623403 | 0.084461962 |
| LDA_03 | 0.01818346 | 0.92554217 | 0.192899042 | 0.034482093 | 0.273580451 | 0.074846263 |
| LDA_04 | 0.01818296 | 0.92711920 | 0.243825177 | 0.050000190 | 0.291901938 | 0.085206741 |
| global_subjectivity | 0 | 1 | 0.454324478 | 0.4537019 | 0.088714114 | 0.007870194 |
| global_sentiment_polarity | -0.39375 | 0.655 | 0.121765939 | 0.120744895 | 0.095362663 | 0.009094037 |
| global_rate_positive_words | 0 | 0.13698630 | 0.040413572 | 0.0390625 | 0.016158490 | 2.61E-04 |
| global_rate_negative_words | 0 | 0.18493150 | 0.01682249946 | 0.01552795031 | 0.01016820589 | 1.03E-04 |
| rate_positive_words | 0 | 1 | 0.703418324 | 0.714285714 | 0.150768549 | 0.022731155 |
| rate_negative_words | 0 | 1 | 0.296453050 | 0.285714285 | 0.150594846 | 0.022678807 |
| avg_positive_polarity | 0 | 1 | 0.361231441 | 0.357851239 | 0.085466977 | 0.007304604 |
| min_positive_polarity | 0 | 1 | 0.099681050 | 0.1 | 0.070616088 | 0.004986631 |
| max_positive_polarity | 0 | 1 | 0.766868375 | 0.8 | 0.212327570 | 0.045082997 |
| avg_negative_polarity | -1 | 0 | -0.26448725 | -0.25371817 | 0.121326146 | 0.014720033 |
| min_negative_polarity | -1 | 0 | -0.52502616 | -0.5 | 0.276797722 | 0.076616979 |
| max_negative_polarity | -1 | 0 | -0.11252072 | -0.1 | 0.094993913 | 0.009023843 |
| title_subjectivity | 0 | 1 | 0.2752389941 | 0.1 | 0.3203594022 | 0.1026301466 |
| title_sentiment_polarity | -1 | 1 | 0.066049355 | 0 | 0.259236988 | 0.067203816 |
| abs_title_subjectivity | 0 | 0.5 | 0.342784586 | 0.5 | 0.188796795 | 0.035644229 |
| abs_title_sentiment_polarity | 0 | 1 | 0.150585880 | 0 | 0.221110011 | 0.048889637 |
| shares | 1 | 843300 | 3395.380184 | 1400 | 11626.95075 | 135185983.7 |

Comentários